Shared compression dictionary: the web's new frontier
Some of the fantastic folks over at Chromium launched a new proposal: compression dictionary transport.
The feature proposed shows great promise for reducing web traffic size and improving page load performance.
In this post, I’ll try to cover the what/where/how of the feature and how we might end up using it, but most importantly: the benefit to end-users.
By the end of the post, I hope to convince you that this feature will shift the web to a new frontier.
Here we go.
Brief history and background
Compression has been a part of the web from very early on.
The content-encoding HTTP header is at least as old as HTTP/1.0 in the 90’s.
For over 15 years Gzip was the most popular encoding choice for both static and dynamic content, with good (de)compression speeds and compression ratios.
In the 2010s, a new compression format arrived on the scene - Brotli.
Thanks to its superior compression ratios, it has became the de-facto compression for static content. For dynamic content, the jury’s mixed [1].
Both Gzip and Brotli incorporate LZ77, so they work with references to previously seen data.
A crude example: the text ABCDEFG-ABCDEFG can be represented more compactly as ABCDEFG-{0,7}, where {0,7} is a reference to previously seen data.
A unique Brotli implementation detail relative to Gzip is the inclusion of a pre-defined dictionary filled with common text, built-in to the spec.
Since both the encoder (server) and decoder (browser) have this dictionary built-in to their Brotli implementations, references can be made to its data - not only to already seen data. This can help achieve better compression ratios.
Brotli supports using external dictionaries as well.
If the same external dictionary is available for use during encoding and decoding, higher compression ratios can be attained (provided the dictionary is relevant to the data being encoded).
Systems that own both ends can reduce data transfer or lower file storage size.
To date, this wasn’t relevant for the web.
Until..
The new shared compression dictionary initiative
The explainer goes into detail.
Simplified bullet points:
- A new mechanism for servers and browsers to share Brotli compression dictionaries
- Path-based scoping dictated by the server (e.g.
/posts/and/recipies/routes can use different dictionaries) - Security via hash of shared dictionary, similar to subresource integrity
Browsers and servers can synchronize shared dictionaries safely, then use them during (de)compression. This which can result in substantially better compression ratios.
Applications and implications for the web
Whether you’re serving a web app or a simple mostly-text document.
Whether you’re rocking a SPA, MPA, island architecture or other hot buzzword.
Shared dictionaries can benefit your users by reducing the amount of data to fetch over the network.
Static resources
A common performance pain point for for web apps is that after a deployment.
Some scripts have changed (usually with cascading effects, i.e. more than we’d like), and the browser has to fetch them from the network. If they’re on the critical path (for application full load or initial render), the user experience suffers.
Combining best practices like code splitting, dynamic imports, tree-shaking, hash-based versioning etc. can help alleviate the pain, but it doesn’t fully solve the problem.
The resulting performance degradation can last for days, until most/all users have the changed resources cached and the impact subsides (for the percentile you follow).
If you deploy more frequently than that - you may have accepted this as your baseline (perhaps unknowingly).
With a shared dictionary mechanism, scripts can serve as the dictionary for the next version of themselves.
- Version N of our script:
myscript-ceeaf54efbc38a24.js. - When the browser fetches it from the network, the server specifies that the script itself is the shared dictionary for the path scope
myscript-(a prefix, it will match anything that follows). - User revisits after deployment.
Browser requests version N+1 of the script,myscript-27c42d7c93ecac67.js. - Instead of sending the regular Brotli-compressed artifact, the CDN sends a version that was Brotli-compressed using
myscript-ceeaf54efbc38a24.jsas a dictionary. We can tell by the response’sVaryheader. - Additionally, the response set
myscript-27c42d7c93ecac67.jsas the dictionary formyscript-the path scope.
The only novel information in the new script is data that doesn’t exist at all in the old version.
This why the shared-dictionary compression artifacts can be substantially smaller. The browser already has most of the data, and it only needs to receive the new parts.
In essence, you can imagine this resulting in only needing to send the delta(diff) between versions. In practice, there’s more than just new data to transmit - references to data in the shared dictionary are compact, but not free.
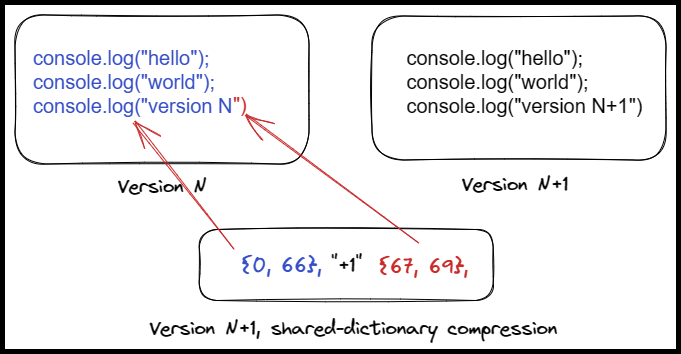
(not an accurate representation of Brotli, demonstration purposes only)
JS size reduction
I took the largest JS asset from some popular public sites, and looked at the size reduction for two consecutive versions.
For results, we’re looking at Brotli level 11.
| Site | Uncompressed | Brotli | With dictionary | Test link |
|---|---|---|---|---|
| Youtube | 2.2 MB | 562 KB (25%) | 114 KB (5%) | results |
| 1.6 MB | 283 KB (17%) | 4 KB (0%) | results | |
| Pintrest | 1 MB | 252 KB (25%) | 9 KB (1%) | results |
The explainer showcases great results even when the versions are months apart.
Next up, the biggest JS asset for large web apps:
| Site | Uncompressed | Brotli | With dictionary | Test link |
|---|---|---|---|---|
| Figma | 16.4 MB | 3.2 MB (20%) | 262 KB (2%) | results |
| Google Sheets | 3.4 MB | 875 KB (26%) | 204 KB (6%) | results |
| Google Slides | 4.1 MB | 1 MB (25%) | 272 KB (6%) | results |
| PowerPoint Online | 3.2 MB | 805 KB (25%) | 299 KB (9%) | results |
| Excel Online | 3.1 MB | 758 KB (24%) | 248 KB (8%) | results |
We won’t avoid network round-trip latencies.
The script won’t load from cache, so no cached code benefits.
Still, the cumulative savings for all modified scripts on the critical path could translate to hundreds of milliseconds (up to seconds) for users on subpar networks.
Shared dictionaries won’t remove the post-deployment price entirely, but they will help flatten the bump. Expect to see higher percentiles accrue more of the benefit (i.e. P99 more than P95, P95 more than P75 etc).
The WebAssembly savior?
I focused on scripts because they hold most of the weight for web apps, but shared dictionaries apply to any static asset.
One of the major pain points for WebAssembly-based apps is a very large up-front download cost.
WASM doesn’t have a built-in standard library, so despite being a binary format which should theoretically be much more compact than JS (source code text), in practice even simple apps can produce large WASM module.
For managed languages with like Go, .NET or Python - the runtime has to be included as well.
On top of all this, there’s no first-class support for code splitting. There are emerging solutions, but they aren’t available for most WASM stacks (even Rust’s).
The entire app is bundled into one giant .wasm file, and if a single line of code is changed - the user has to fetch the whole thing from scratch. I hope you see where this is going..
| App | Uncompressed | Brotli | With dictionary | Test link |
|---|---|---|---|---|
| Google Earth | 21.4 MB | 4.5 MB (21%) | 1.2 MB (6%) | results |
| Figma | 18.5 MB | 3.7 MB (20%) | 7 KB (0%) | results |
| Ruffle | 11.1 MB | 2.7 MB (24%) | 803 KB (7%) | results |
Whole Megabytes shaved.
Moving towards only the very first load of a WASM-based app being excessively slow. From then on, the web equivalent of a binary delta will be used for updates.
How many new WASM-based web apps just became viable? Did I say new frontier yet?
I have to mention that I’m not sure whether Figma’s example is the exception or the rule. My suspicion is that for Ruffle and Google Earth, large changes took place between versions (likely to be changes in compilation, rather than big code rewrites). Wish the sample size was larger, but I had a hard time finding large WASM web apps where previous versions are discoverable.
Even if the Figma example is the exception, I can’t help but wonder if the compression gains could dramatically increased with specialized tooling.
I’m way out of my depth here, but I’ll throw some ideas:
- Can dictionary creation be specialized for WASM?
- Compilers aiming to keep changes to a minimum, based on a previous version’s build metadata (similar to PGO aiding the compiler with optimizations)?
- Allowing for more bloated uncompressed code, which ends up compressing better overall? (possibly sacrificing some run time efficiency as well)
Dynamic resources
For dynamic resources, the flow is similar:
- HTML contains a
<link rel="dictionary"... > - The browser fetches the dictionary when idle is reached (Proposal doesn’t specify, assume
requestIdleCallback-esque) - Server response has a
use-as-dictionaryheader to set the path scope.
Pages
For dynamic pages the size reduction isn’t as extreme, both in relative and absolute terms.
For the tests in this section, a mobile user-agent was used. For results, we’re looking at Brotli level 5.
Search results and product pages for unrelated terms still see a sizeable reduction:
-
Page Uncompressed Brotli With dictionary Homepage 162 KB 47 KB (29%) 23 KB (14%) “used cars” 758 KB 140 KB (18%) 72 KB (10%) “washing machine” 1,470 KB 238 KB (16%) 171 KB (12%) “the dragon book” 716 KB 195 KB (27%) 124 KB (17%) -
Page Uncompressed Brotli With dictionary Homepage 88 KB 27 KB (31%) 13 KB (15%) “used cars” 347 KB 89 KB (26%) 21 KB (6%) “washing machine” 556 KB 137 KB (25%) 58 KB (11%) “the dragon book” 428 KB 121 KB (28%) 45 KB (11%) -
Page Uncompressed Brotli With dictionary Homepage 628 KB 175 KB (28%) 111 KB (18%) Search “phone charger” 996 KB 111 KB (11%) 43 KB (4%) Search “tooth brush” 940 KB 108 KB (12%) 41 KB (4%) Product page - book 1,955 KB 302 KB (15%) 150 KB (8%) Product page - chocolate 2,126 KB 309 KB (16%) 159 KB (9%)
Don’t get swayed by the results and see the forest for the trees (I know I did for a moment..).
For most of these pages (and most of the web, really) images are the network hogs. Additionally, the the HTML is streamed so above-the-fold HTML (filling the screen/viewport) is received ASAP.
I’m not sure the user experience would change much, if at all.
Trying websites with (ostensibly/usually) a focus on text:
-
Site Uncompressed Brotli With dictionary Homepage 616 KB 128 KB (21%) 112 KB (18%) Article 1 179 KB 32 KB (18%) 6 KB (4%) Article 2 225 KB 48 KB (22%) 19 KB (9%) Article 3 359 KB 60 KB (17%) 31 KB (9%) -
Site Uncompressed Brotli With dictionary Homepage 75 KB 16.8 KB (22%) 15.9 KB (11%) Article 1 318 KB 52 KB (17%) 40 KB (13%) Article 2 305 KB 54 KB (18%) 42 KB (14%) Article 3 395 KB 44 KB (11%) 32 KB (8%)
Based on the results, I’m not convinced using shared dictionaries for dynamic pages will be game-changing.
User experience impact might hinge on whether a single round-trip is shaved.
Keep in mind, the dictionary built by the tool is based on all other pages than the one tested. Better results can be obtained with specialized/smarter dictionary creation.
For example, for Wikipedia it probably makes sense to create a dictionary containing common words of in the page’s language (Brotli’s built-in dictionary only has a mix of common words from 6 languages).
Interesting tidbit/shower thought:
Shared dictionaries are pre-computed like any other static asset. So they’ll get compressed with level 11 Brotli and that’s the artifact that will be sent to the client.
The go-to dynamic compression level is 3-4. Compressing dynamic pages with level 11 is unthinkable due to the slow compression speed, but suddenly there’s an avenue to smuggle large parts of the page with level 11 compression.
I don’t have a use case in mind, but I feel like this can be positively abused somehow. A scenario where it’s worth initiating and waiting for a dictionary load to complete before performing a navigation to a path in its scope.
Implications for SPA vs MPA
A popular selling point for SPAs is that by only fetching and rendering data relevant to an interaction, the E2E time (from interaction to paint) is faster than it would be with a MPA setup, where a full page would be fetched and re-rendered.
Shared compression dictionaries change the power dynamic.
The more a page consists of static(or predictable) content, the more the line between a SPA and MPA is blurred.
Fetching-wise, what’s the difference between hitting a JSON endpoint and receiving a Brotli-encoded delta for a full page (for which static resources are cached)? Network latency will be the dominating factor for both.
Rendering-wise, is VDOM-diffing + component function execution necessarily going to be faster than parsing and displaying a raw HTML page from scratch? I’m not convinced the former will always be faster. (I’ll acknowledge that fine-grained reactivity probably wins more often.)
We’ll have to wait for RUM results, but my hunch is that the bar has been raised.
A higher session depth will be needed for a SPA architecture to pay off.
Dynamic data
Much like dynamic pages, HTTP-based API’s could provide shared dictionaries too.
I’d guess that for most APIs the payload is too small for the difference to matter, but maybe I’m wrong.
WebSocket and WebTransport can’t make use of the feature as they don’t communicate over HTTP.
Onboarding
What work will be needed for our websites to utilize the feature?
Static assets
For the most common setup where the CDN fetches resources from an origin server, the exchange might be as follows (simplified/not addressing all cases for brevity):
- When a request comes in it’ll have to inspect the
sec-available-dictionaryheader and try to match it to a shared-dictionary compressed artifact - If it doesn’t exist, try and fetch it from the origin server
- If the server responds with a
varyheader indicating the response is a shared-dictionary artifact, cache it (with a mapping from the hash).
So what we’ll need to is:
- Somewhere along the CI/CD path, create the shared dictionary-based compressed artifacts, in addition to the regular Brotli-compressed artifact.
- Have our origin server(s) add the
use-dictionaryto the response (for appropriate assets), and inspect incoming requests for thesec-available-dictionaryheader.
For setups where all assets are pre-uploaded to the CDN directly, the CDN will have to provide a full solution.
Dynamic pages
For dynamic pages, the interaction between the web server and the application, which can define arbitrary routes, is divided. For some stacks its common for the web server to handle compression, and for others the web application.
For stacks where the web server handles compression, it might not be immediately obvious where shared dictionary logic should reside.
On one hand, the web server currently takes care of response compression, completely transparent to the application.
On the other hand, since the shared-dictionary is path-scoped, it makes sense for the application handle it.
Assigning the responsibility to the web server means web framework’s will need to be capable of outputting configuration for it.
Several issues immediately come to mind, which make this seem like the wrong choice:
- For dynamic languages like Python, Ruby, and Javascript some form of an unnatural “build step” needs to be introduced. Even for compiled languages, static analysis might not be straightforward.
- Web server’s don’t have some unified DSL. Web framework’s will need to support web servers individually. The maintenance burden is huge.
- What about dynamic routes? i.e. routes added during runtime
That doesn’t make sense. So to the application layer we’ll go!
A common trick to steal the compression responsibility from the web server is to remove the request’s accept-encoding header and return a compressed response. The web server will pass the bytes along without touching them.
Adoption and friction
Browser support
Unless a serious privacy or security concern surfaces, I think all browsers will quickly follow in Chromium’s footsteps and implement the feature.
There’s too much end-user perf goodness to leave on the table.
CDN support
CDN pricing is metered by transfer size, $/GB transferred.
I can’t imagine much enthusiasm to invest in a revenue-reducing feature. There seems to be an inherent conflict of interest.
I hope I’m grossly misinformed on the biz. (How did they view Brotli when it came along?)
Big players lead the way
Organizations with a high level of performance management maturity, that stand to reap large rewards, will put in the work for their tech stacks.
They’ll lead the charge to the new frontier, and over time the web as whole will benefit.
For static content:
Companies like Google and Microsoft will onboard their GSuite/M365 web apps’ static content.
For dynamic pages:
Ecommerce companies like Amazon, Shopify, Ebay (to name a few) will be first in line to experiment.
With billions of users across the globe, the big players can afford to invest, experiment and (if results are positive) reap rewards.
Hopefully they’ll share some results publicly, encouraging (or discouraging) adoption.
Ideas for the future
After my excitement settled down, I started wondering if this feature could be leveraged further. Here are a few (very premature) ideas I had:
-
Pre-compressed sections
Even the most dynamic page has some static parts.
Could we pre-compress these parts once (with the shared-dictionary), then use them when building responses? This could reduce CPU-bound compression work.I bounced this idea to Jyrki Alakuijala (one of the designers and implementors of Brotli), and his response was positive on the Brotli side. Meaning, there exist foundations in Brotli making this technically possible.
Assuming doing so results in a net gain (for example, doesn’t hurt decompression speeds), the question is then:
Can web frameworks conveniently pre-compress static sections and use them? Will the DX be good enough, friction low enough, to make the gains worthwhile?Maybe one day we’ll find out.
-
JavaScript diffing support
Currently, all browsers have some form of bytecode caching for scripts. However, when a new script/version is downloaded, it has to be parsed from scratch. The browser doesn’t know that this new script is a new version of that other older script it has cached.Now that there ~is such an indication, could some parsing work be eliminated or reduced if the JS engine is provided with the older script’s version and its cached bytecode?
My gut feeling is that this is impossible rubbish, and that even if it isn’t, it wouldn’t be worth the effort.
Sharing for v8/JSC folks amusement at my expense.
A final word
This is my first blog post. I’m not much of a writer, but that’s ok, we all gotta start somewhere.
I’m more worried about having made a fool of myself with technical mistakes or obvious oversights.
If you have any feedback, feel free to send it my way - [email protected]
Footnotes
[1]:
In the years following Brotli’s initial release, the popular consensus was that for
dynamic content Brotli’s better compression ratios didn’t compensate for the slower
compression speeds vs Gzip.
In more recent years, I’ve found several posts that claim
this to be false, in some cases showing misconfigurations by past posts.
The squash compression benchmark doesn’t have representative
JS, CSS or WASM files, but the results seem to support claims that Brotli level 3-4
hit a sweet spot.
For shared dictionary compression, Patrick Meenan’s test site
shows improvements only from Brotli level 5 and up. I haven’t dug into why. My guess
is it’s a by-design limitation on the sliding window size for the lower levels.
Brotli level 5 is a significant jump in compression speed slowdown. If the compression ratio
gain is substantial, it’ll more than outweigh the cost. Meaning, E2E time for the
user will decrease.
If your machines aren’t at their CPU limit, this probably won’t
come up at all. If you’re rolling serverless, I doubt your bills will increase beyond a rounding error.